深層学習でダメ絶対音感を作ってみた
2018/02/03
この前、Amazonプライム・ビデオで「がっこうぐらし!」を見たんですけど、主人公のゆきの声が「けいおん」の唯の声の豊崎愛生さんに聞こえてしまって、そういえば豊崎愛生さん結婚しちゃったんだよなぁと感傷にふけっていたら、ゆきのCVは水瀬いのりさんでした……。
あれ? 年を取ってモスキート音が聞こえなくなっただけじゃなくて、ダメ絶対音感も衰えてる?
老眼は遠近両用メガネで対応できたのですけど、ダメ絶対音感対策デバイスはAmazonでも見つかりません。しょうがないので、自分で作りました。
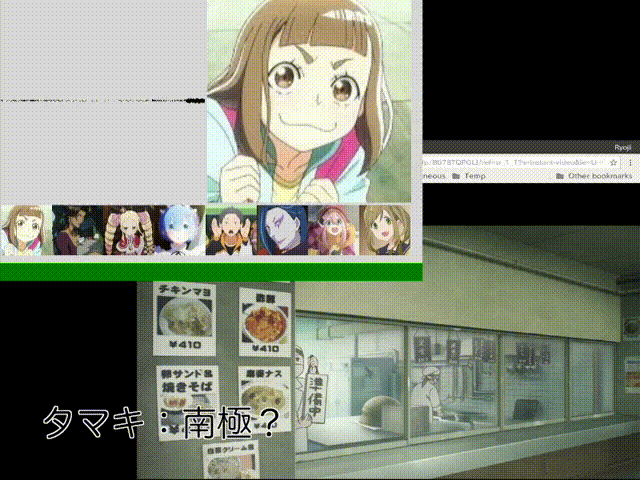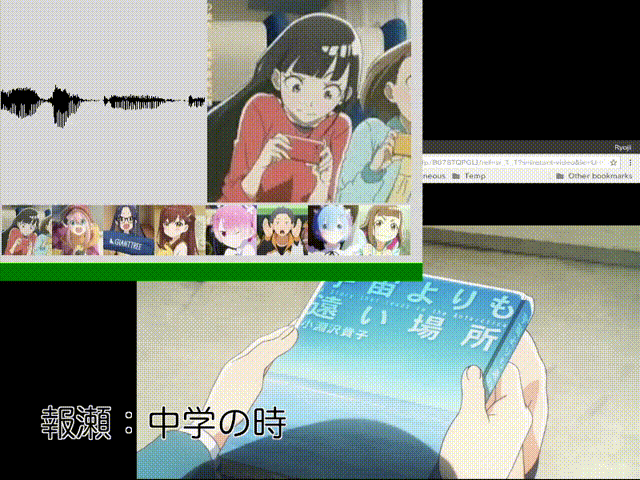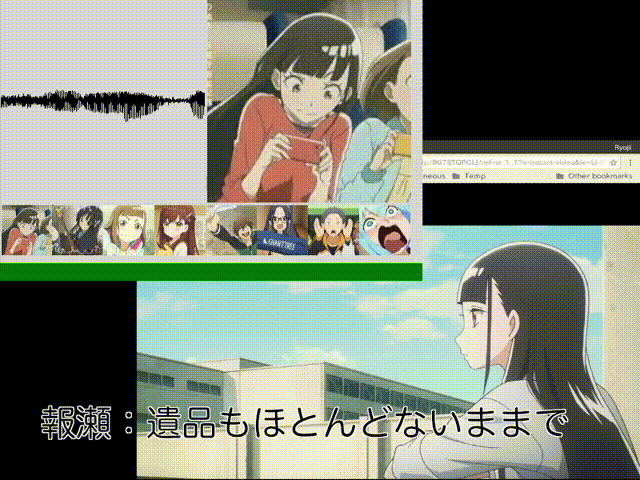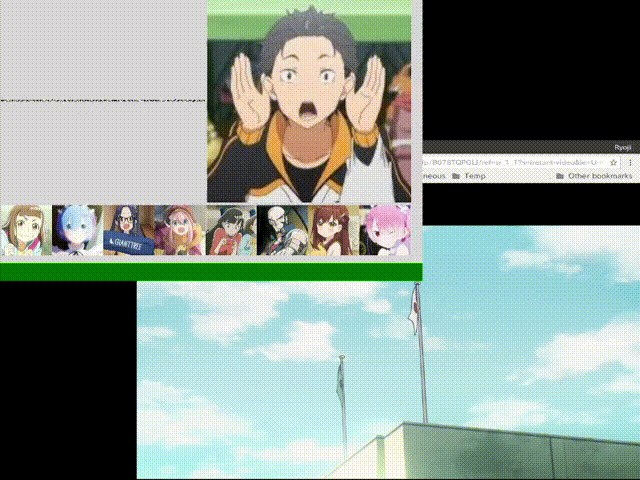
#ダメ「相対」音感くらいはできたかなぁと。あ、タマキじゃなくてキマリだった……。
データ集め
まずは、適当に選んだ以下のビデオの音声を録音しました。
- Re:ゼロから始める異世界生活(5話)
- がっこうぐらし!(5話)
- この素晴らしい世界に祝福を!2(2話)
- ゆるキャン△(2話)
- カウボーイビバップ(1話)
- 宇宙よりも遠い場所(2話)
- 映画「けいおん!」
録画した音声を、ツール(私が使用したのはAudacity)を使用して0.2秒の無音部分で分割していきます。
分割した音声ファイルを1つずつ聞いて、うまいことキャラクター単位に分かれたファイルだけを抽出して、キャラクター単位に分けます(深層学習が音楽を消すフィルターを作って人間の声の特徴だけを抽出してくれることを期待して、後ろで音楽が流れていても気にしない)。
キャクター単位で音声ファイルを結合して0.5秒単位で分割して、音声のままだとデータが大きすぎて大変そうだったので、MFCC(メル周波数ケプストラム係数)で44×44のデータに変換して、教師データとします。データ件数は、8,349件になりました。
注意!
実は私、音声は素人です。あと、深層学習も趣味レベルです。ただのプログラミング好きなおっさんなんですよ……。
さっきはさらっとMFCCとか書いちゃいましたけど、MFCCが具体的にどんなことをしているのか全く理解していません。プロが見たらおかしなことをやっていると思いますので、ご指摘してくださるようお願いいたします。
学習
音声は持続性があるデータなので、本当は再帰型のニューラル・ネットワークを使ったほうが良い気がしますけど、使い慣れた畳み込みニューラル・ネットワークで押し通しました(0.5秒で分割しちゃったし)。その畳込みニューラル・ネットワークも借り物で、WideResNetを使用しました。コードは、以下のような感じ。Kerasを使うと、私のような素人でも簡単に深層学習できますな。
import pickle
from data_set import load_data # データ読み込み
from funcy import identity, juxt, partial, rcompose, repeatedly # 関数型プログラミング・ライブラリ。便利!
from keras.callbacks import ReduceLROnPlateau
from keras.layers import Activation, Add, AveragePooling2D, BatchNormalization, Conv2D, Dense, GlobalAveragePooling2D, Input
from keras.models import Model, save_model
from keras.optimizers import Adam
from keras.regularizers import l2
from utility import ZeroPadding # ゼロ詰めしたテンソルで次元数を増やすユーティリティ。
def computational_graph(class_size):
# Kerasはシーケンスが嫌いみたいなので、リスト化するバージョンのjuxtを作っておきます。
def ljuxt(*fs):
return rcompose(juxt(*fs), list)
# 以下、Kerasのラッパーです。
def add():
return Add()
def average_pooling():
return AveragePooling2D()
def batch_normalization():
return BatchNormalization()
def conv(filters, kernel_size):
return Conv2D(filters, kernel_size, padding='same', kernel_initializer='he_normal',
kernel_regularizer=l2(0.0001), use_bias=False)
def dense(units):
return Dense(units, kernel_regularizer=l2(0.0001))
def global_average_pooling():
return GlobalAveragePooling2D()
def relu():
return Activation('relu')
def softmax():
return Activation('softmax')
def zero_padding(filter_size):
return ZeroPadding(filter_size)
# WideResNetの計算グラフ。
def wide_residual_net():
def residual_unit(filter_size):
return rcompose(ljuxt(rcompose(batch_normalization(),
conv(filter_size, 3),
batch_normalization(),
relu(),
conv(filter_size, 3),
batch_normalization()),
identity),
add())
def residual_block(filter_size, unit_size):
return rcompose(zero_padding(filter_size),
rcompose(*repeatedly(partial(residual_unit, filter_size), unit_size)))
return rcompose(conv(16, 3),
residual_block(160, 4),
average_pooling(), # 個人的な好みで、ストライドではなくて平均プーリング。
residual_block(320, 4),
average_pooling(),
residual_block(640, 4),
global_average_pooling())
# 計算グラフを返します。WideResNetの出力を、全結合層で256次元→32次元と段階的に小さくして、ソフトマックスします。
return rcompose(wide_residual_net(),
dense(256),
dense(class_size),
softmax())
def main():
# 教師データを読み込みます。
(x_train, y_train), (x_validate, y_validate) = load_data()
# 正規化のためのパラメーター。
x_mean = -14.631151332833856 # x_train.mean()
x_std = 92.12358373202312 # x_train.std()
# xを正規化して、Kerasのconvが通るように[?, 44, 44, 1]に形を変えます。
x_train, x_validate = map(lambda x: ((x - x_mean) / x_std).reshape(x.shape + (1,)), (x_train, x_validate))
# yのデータは[?, 2(0が声優で1がキャラクター)]になっているので、キャラクター部分だけを取ります。
y_train, y_validate = map(lambda y: y[:, 1], (y_train, y_validate))
# モデルを生成します。
model = Model(*juxt(identity, computational_graph(max(y_validate) + 1))(Input(shape=x_validate.shape[1:])))
model.compile(loss='sparse_categorical_crossentropy', optimizer=Adam(lr=0.0005), metrics=['accuracy'])
model.summary()
# 学習します。バッチ・サイスは100、エポック数はとりあえず大きく400にしてみます。GPUのメモリが少ない場合は、バッチ・サイズを減らしてみてください。
results = model.fit(x_train, y_train, batch_size=100, epochs=400,
validation_data=(x_validate, y_validate),
callbacks=[ReduceLROnPlateau(factor=0.5, patience=20, verbose=1)])
# 学習履歴を保存します。
with open('./results/history.pickle', 'wb') as f:
pickle.dump(results.history, f)
# モデルを保存します。
save_model(model, './results/model.h5')
# 必要か分からないけど、モデルを破棄します。
del model
if __name__ == '__main__':
main()
学習の結果、適当により分けておいた検証データでの精度が80%を超えました。これならダメ絶対音感も実現できそうです。
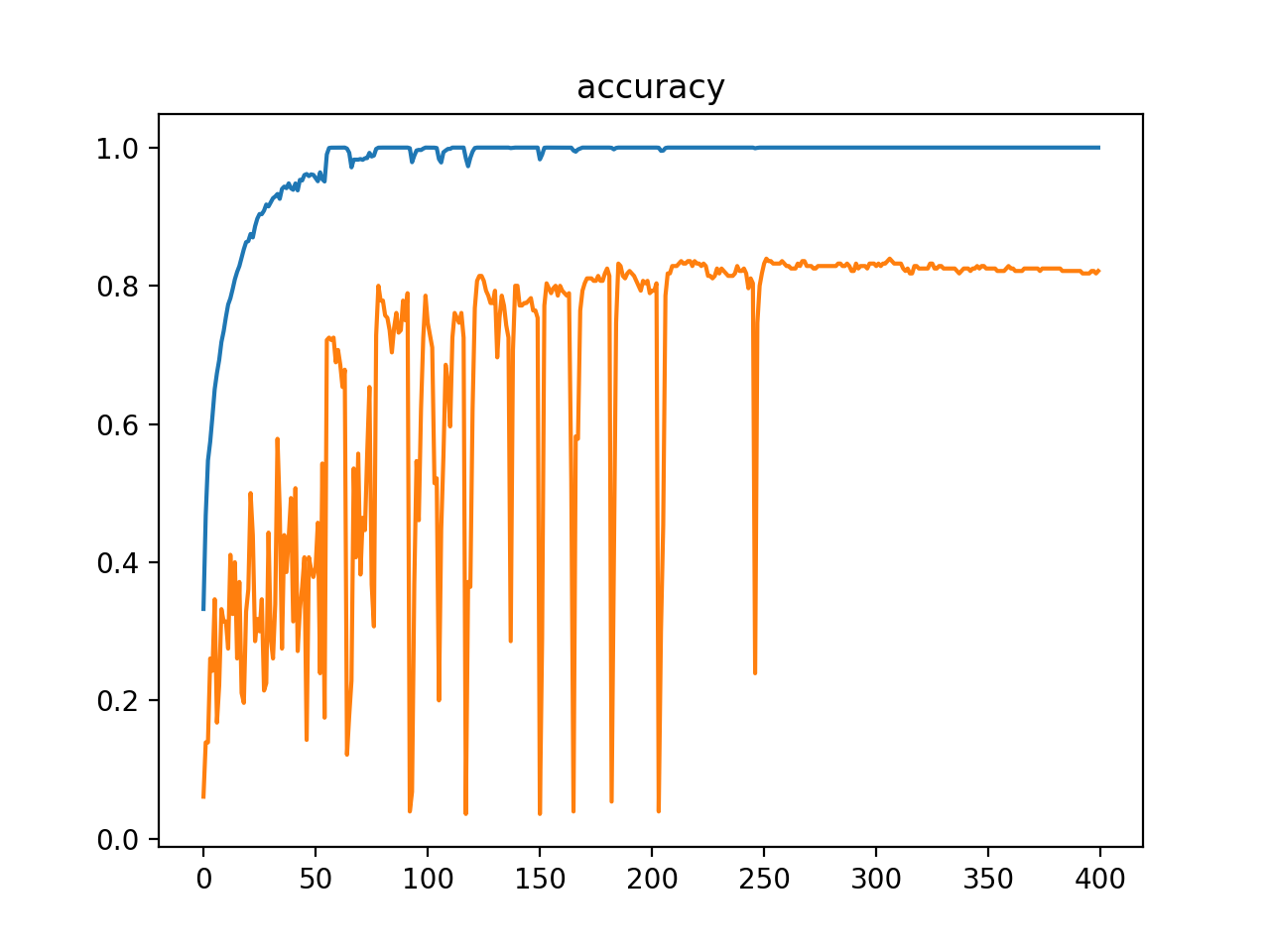
#エポック数は300くらいが良かったかも……。
ダメ絶対音感
録音はPyAudioで、MFCC化はlibrosaで実施しました。とても楽ちんです。
import librosa
import numpy as np
import os.path as path
import pyaudio
import tensorflow as tf
from funcy import first, second
from keras.models import load_model
from useless_absolute_pitch_frame import UselessAbsolutePitchFrame
from utility import ZeroPadding, child_paths
# キャラクター・データのパスを取得します(キャラクター・データのパスに画像データが入っているため)。
def character_paths():
for actor_path in filter(path.isdir, child_paths('./data/validate')):
for character_path in filter(path.isdir, child_paths(actor_path)):
yield character_path
# メイン・ルーチン。
def main():
# PyAudioのコールバック。
def stream_callback(data, frame_count, time_info, status):
# コールバックは別スレッドになるので、使用するグラフを指定しないとTensorFlowが動きませんでした。
with graph.as_default():
# 音声データをNumPy化します。
wave = np.frombuffer(data, dtype=np.float32)
# MFCC化します。n_mfccが44なのは、0.5秒だと横方向が44になったためです。
mfcc = librosa.feature.mfcc(wave, sr=44100, n_mfcc=44)
# 正規化し、モデル作成時のInputと同じなるように[?, 44, 44, 1]に形を変えてxにします。
x = ((mfcc - -14.631151332833856) / 92.12358373202312).reshape((1,) + mfcc.shape + (1,))
# キャラクターを推論します。
y = model.predict(x)
# 後述するGUIに表示するように命令します。
gui.draw_predict_result(wave, tuple(map(second, reversed(sorted(zip(y[0], range(len(y[0]))), key=first)))))
# 続けて処理するよう、PyAudioに指示します。
return data, pyaudio.paContinue
# PyAudio。便利!
audio = pyaudio.PyAudio()
# モデルの読み込み。PyAudioのコールバックが別スレッドなので、TensorFlowの計算グラフを保存しておきます。
model = load_model('./results/model.h5', custom_objects={'ZeroPadding': ZeroPadding})
graph = tf.get_default_graph()
# PyAudio経由で録音。
stream = audio.open(format=pyaudio.paFloat32, channels=1, rate=44100, input=True,
frames_per_buffer=22050, stream_callback=stream_callback)
stream.start_stream()
# 後述するGUIを生成。
gui = UselessAbsolutePitchFrame(tuple(character_paths()))
gui.mainloop()
# 終了処理。
stream.stop_stream()
stream.close()
audio.terminate()
if __name__ == '__main__':
main()
GUI部分はtkinterで作りました。tkinterが使いづらくて、ここに一番時間がかかりました……。コードが汚いですけど、リファクタリングはまた今度で。
import numpy as np
import os.path as path
from funcy import count, juxt, map
from tkinter import *
from tkinter.ttk import *
class UselessAbsolutePitchFrame(Frame):
def __init__(self, character_paths, master=None):
super().__init__(master)
# キャラクターの画像を取得。tkinterのPhotoImageって、GIFかPPMじゃないとダメだと知らなくて、ひどい目にあいました。
self.character_images = tuple(map(lambda character_path: PhotoImage(file=path.join(character_path, 'image.ppm')), character_paths))
self.character_small_images = tuple(map(lambda character_path: PhotoImage(file=path.join(character_path, 'small_image.ppm')), character_paths))
# GUIを生成します。
self.master.title('ダメ絶対(?)音感')
self.create_widgets()
self.pack()
# GUIを生成します。
def create_widgets(self):
frame_1 = Frame(self)
# 音声の波形を表示するためのキャンバス。
self.wave_canvas = Canvas(frame_1, width=256, height=256)
self.wave_canvas.grid(row=0, column=0)
# 推論したキャラクターを表示するためのキャンバス。
self.character_canvas = Canvas(frame_1, width=256, height=256)
self.character_canvas.grid(row=0, column=1)
frame_1.pack()
frame_2 = Frame(self)
# 推論結果の確率が高い順に、キャラクターをソートして表示するためのキャンバス。
self.characters_canvas = Canvas(frame_2, width=512, height=64)
self.characters_canvas.pack()
frame_2.pack()
# 推論結果を表示します。
def draw_predict_result(self, wave, character_indice):
self.draw_wave(wave)
self.draw_predicted_character(character_indice[0])
self.draw_predicted_characters(character_indice)
self.update()
# 音声の波形を表示します。
def draw_wave(self, wave):
min_ys, max_ys = zip(*map(juxt(np.min, np.max), np.array_split(wave * 128 + 128, 256)))
for object_id in self.wave_canvas.find_all():
self.wave_canvas.delete(object_id)
for x, min_y, max_y in zip(count(), min_ys, max_ys):
self.wave_canvas.create_line(x, min_y, x, max_y)
# 推論したキャラクターを表示します。
def draw_predicted_character(self, character_index):
for object_id in self.character_canvas.find_all():
self.character_canvas.delete(object_id)
self.character_canvas.create_image(128, 128, image=self.character_images[character_index])
# 推論結果の確率でソートして、可能性が高い順にキャラクターを表示します。
def draw_predicted_characters(self, character_indice):
for object_id in self.characters_canvas.find_all():
self.characters_canvas.delete(object_id)
for i in range(8):
self.characters_canvas.create_image(i * 64 + 32, 32, image=self.character_small_images[character_indice[i]])
ともあれ、これで完成! 録音したのとは異なる話数のビデオをAmazonプライム・ビデオで流しながら試してみたら、冒頭のアニメーションGIF(まぁ、これはいくつか試した中で良かった場合の例なのですけど。あと、ダメ絶対音感の方を0.5秒すすめるかたちで編集しています)で示したみたいにそれなりの精度で判定をしてくれるんだけど、誰も喋っていないところ(左上の音声の波形が小さい時)でガチャガチャ推測結果が変わって落ち着きません。
人が喋っているのかいないのかを判断する技術が必要……なんですけど、素人なのでその方法が思いつきません。誰か助けてください……。このままだと、ゆるふわ系主人公のアニメを見るたびに、豊崎愛生さん結婚ショックがぶり返しちゃう!
参考
音楽と機械学習 前処理編 MFCC ~ メル周波数ケプストラム係数 ←MFCCはここで知りました。最初のコードの部分以外は、全く理解できませんでしたが……。
devil-ear ←本稿で作成したコードです。