今年49歳になるおっさんでも作れたAlphaZero
2018/06/20
前回やったモンテカルロ木探索は、けっこう強くて面白かった。でも、人間の欲には限りがありません。もう少しだけ、強くできないかな? それ、話題の深層学習ならできます。そう、AlphaGoの後継のAlphaZeroならね。
#作成したコードはこちら。
モンテカルロ木探索で、なんとなく不満なところ
モンテカルロ木探索では、UCB1というアルゴリズムで手を選んでいました。で、このUCB1なんですけど、とりあえず1回は全部の手を試すところが嫌じゃないですか? 相手がリーチをかけてきたら、防ぐ以外の手は考えられません。でもUCB1だとそれ以外の手も試さなければならないという……。会社で明らかにダメなプロダクトを使えと言われて、いかにダメかを口頭で説明して、でも意識高げな詐欺師に騙されちゃってるみたいで聞く耳持ってもらえなくて無駄な評価作業を開始するときのような感じ。プログラム組めない奴がプロダクトを選定するの禁止しろよ! 関数型言語による生産性向上率を測定しろというような、技術的に正しい作業をしたいなぁ……。
で、プロダクト選定はともかくとして、局面を入力にしてどの手を選ぶべきかを出力する程度なら、深層学習でできるんですよ。だって、写真に写っているのが飛行機か自動車か鳥か猫か鹿か犬か蛙か馬か船かトラックなのかを出力できちゃうのですから、局面を入力に次に指すべきマスが左上か中央上か右上か残りのどこかなのかを出力するぐらいできて当たり前。精度はそれほど高くなくて、間違えまくるでしょうけど。
あと、プレイアウトを繰り返して局面の価値を測定するのも、なんだか処理が重そうで嫌じゃないですか? ダブル・リーチをかけられたら、考えるまでもなく最悪の局面なはず。でも、何度もプレイアウトしてどれだけ悪いかを確かめなければなりません。同じシステムを何度も作るみたいな感じ。経験がないプログラミング言語を使ってよいなら、同じシステムでも勉強になるので大歓迎ですけど。みんな一度はClojureをやってみると良いと思うよ。あれは、いいものだ。
でね、システムを作るのは無理ですけど、局面を入力にして価値を出力する程度なら、深層学習でできるんですよ。だって、写真を入力にインスタグラムでいいねがもらえるかどうかを出力できちゃうんですから。局面を入力に+1.0から-1.0の間の数値を出力するなんて朝飯前です。精度が足りなくて、良いと出力された局面を選んだのに窮地に追い込まれたりするでしょうけど。
まとめます。深層学習なら、次にどの手を指すべきかとか、局面の価値とかを出力することだできます。でも、今のところ、精度はあまり高くありません。AlphaGoの開発で、あのGoogle様が頑張っても、次の一手が人間の強いプレイヤーと一致する確率は57%程度だったそうです。だから、深層学習の出力をただ使うだけでは、そんなに強くはなりません。でも、この2つの値をモンテカルロ木探索に組み込んだら?
モンテカルロ木探索への組み込み
とりあえず、深層学習で次の一手と局面の価値を出力できるものとしてください。predict()という関数があって、その関数は深層学習の魔法でアクション毎の推奨度(Googleはポリシーと読んでいるので、以後ポリシー)と、局面の価値を返すものとします。
>>> predict(State())
([0.1, 0.6, 0.1, 0.05, 0.02, 0.03, 0.1, 0.0, 0.0], 0.78) # [0.1...]がポリシー。アクション単位での確率です。0.78が局面の価値。仮なので、でたらめな値ですけど
このpredict()関数を使う、モンテカルロ木探索のコードを考えてみます。最初に問題になるのはポリシーを考慮していないUCB1の部分ですけど、幸いなことに、Googleが式を定義してくれました。
w / n + C_PUCT * p * sqrt(t) / (1 + n)
# wはこのノードの価値
# nはこのノードの評価回数
# C_PUCTはバランスを調整するための定数。とりあえず1.0でよいみたい。
# pはポリシー
# tは総評価回数
……どうしてUCB1と大きく違うんだろ? 数学上の秘密があるのでしょうけど、どうせ49歳のおっさんな私には理解できませんから、この式をそのまま使います。UCB1のlogより、この式のsqrtの方が少しだけ馴染みがありますしね。プログラム面では、ポリシーのpをnodeクラスに追加する程度の影響しかないですし。
残る作業は、playout()の代わりにpredict()を呼び出すように変更して、ルート・ノードもポリシーを取得するためにpredict()を呼び出すからexpand()をメソッドとして切り出すのをやめるだけ。さっそく作ってみましょう。
class node:
def __init__(self, state, p):
self.state = state
self.p = p # 方策
self.w = 0 # 価値
self.n = 0 # 試行回数
self.child_nodes = None # 子ノード
def evaluate(self):
if self.state.end:
value = -1 if self.state.lose else 0
self.w += value
self.n += 1
return value
if not self.child_nodes:
policies, value = predict(model, self.state)
self.w += value
self.n += 1
self.child_nodes = tuple(node(self.state.next(action), policy) for action, policy in zip(self.state.legal_actions, policies))
return value
else:
value = -self.next_child_node().evaluate()
self.w += value
self.n += 1
return value
def next_child_node(self):
def pucb_values():
t = sum(map(attrgetter('n'), self.child_nodes))
# child_node.nが0の場合に大きな値を設定してしまうと結局全部の手を試してみることになってしまうので、-1から1の中央の0を設定しました。
return tuple((-child_node.w / child_node.n if child_node.n else 0.0) + C_PUCT * child_node.p * sqrt(t) / (1 + child_node.n) for child_node in self.child_nodes)
return self.child_nodes[np.argmax(pucb_values())]
お時間があったら、前回のモンテカルロ木探索のコードと見比べてみてください。モンテカルロ木探索のコードとほとんど同じで、むしろ単純になっています。predict()の第一引数のmodelは深層学習のモデルで、深層学習で処理するときに必要になるモノです。とりあえず無視してください。
ただ、このnodeクラスを「使う」部分は、少し複雑です。というのも、深層学習には「学習」って名前がついていて、コンピューターにおける学習ってのは大量のデータを食わせていく作業を指すので、そのデータを作るための工夫が必要なんですよ。
強化学習
もし、あなたがマルバツの棋譜を数万枚持っているなら、その棋譜をデータ化して学習させることが可能です。その場合は、モンテカルロ木探索の場合と同様にnodeクラスのnを使って次の一手を返す関数を作ればオッケー。でも、私はそんなマニアックな棋譜は持っていませんから、コンピューターに学習データを生成させることにしました。
学習に必要なデータは入力と出力のペアで、今回は、入力が局面で出力がポリシーと価値です。学習とは、こんな入力のときはこんな出力が正解だからねってのを繰り返しコンピューターに教え込んでいく作業なんですよ。で、入力の局面はよいとして、出力であるポリシーと価値の正解データはどうしましょうか? ポリシーも価値も正解が分からないから、それを探索するプログラムを組んでいるのに……。
で、単純すぎてビックリなのですけど、勝った場合はその勝ちに至る局面の「価値」を1、負けた場合は-1を正解としちゃっていいんだそうです。学習後にさらに対戦させてデータをとって、そのデータでさらに学習させてさらにさらに対戦させてデータを取って……ってのを繰り返してよいなら、こんなに単純なやり方でも多くの場合でうまくいくみたい。でも、「ポリシー」はどうしましょうか? 勝った手のポリシーを増やして、負けた手のポリシーは減らすのかな? 増やしたり減したりといっても、どれくらいがよいの?
にわかには信じられないのですけど、今回の対戦で得たモンテカルロ木探索のnの値を正解にしちゃえばよいらしい。考えてみましょう。勝ったにせよ負けたにせよnの値はモンテカルロ木探索を頑張った結果なわけで、深く読むべき局面と浅く読むべき局面を表現している、正解に近い値だと考えることができます。あと、価値が正しく設定されるなら、その価値に沿う形に次回の対戦でのnが変わって、次は今よりもさらに正解に近い値となるはずです。
ともあれ、学習するにはnの値を保存しておかなければならないことが分かったわけで、だからまずはnの値を返す関数を作ります。
def pv_mcts_scores(model, evaluate_count, state):
# 先程のnodeクラスは、ここに入ります。これでpredict()の引数のmodelは、引数のmodelがそのまま使われます。
root_node = node(state, 0)
for _ in range(evaluate_count):
root_node.evaluate()
return tuple(map(attrgetter('n'), root_node.child_nodes))
関数名の先頭のPVはPolicy Valueの意味で、MCTSはMonte Carlo Tree Searchの意味です(AlphaZeroのアルゴリズムは、この前に更にAsynchronous(非同期)のAがついたAPV MCTSと呼ぶみたい)。見ての通り、この関数はnそのものを返します。
で、もう一つ。学習をさせるには、ランダム性の追加をしなければなりません。深層学習では、入力が同じであれば同じ結果を出力します。マルバツの最初の局面は毎回同じ(何も記入されていない空の盤面)なので、それを入力にしたpredict()の出力も毎回同じになります。そして今回作成したコード中にはランダムは含まれませんから、pv_mcts_scores()の戻り値も、やはり毎回同じになります……。これでは何回対戦しても同じ棋譜しか得られなくて、学習が成り立ちません。どうにかしてランダム性を追加して、学習データのバリエーションを増やしたい。
すぐに思いつくのは時々ランダムで適当な手を選ぶ方式(εグリーディという大層な名前がついています)ですけど、AlphaZeroはそれより良い方式を採用しています。nの値を確率とみなして、確率的に手を選ぶという方式です。でも、本番の試合では、最高の手だけを指して欲しいですよね? あと、学習データを作成する場合でも、学習初期はランダム性を大きく設定したバリエーションが豊富なデータが、学習の後期にはランダム性を小さくした精度の高いデータが欲しかったりするかもしれません。
こんなワガママを叶えるためにAlphaZeroが採用したのが、ボルツマン分布ってやつみたい。で、ボルツマン分布の式を見たのですけど私では全く理解できなかったので、GitHubを検索して見つけた中で一番分かりやすかったコードを入れてみました。
def boltzman(xs, temperature):
xs = [x ** (1 / temperature) for x in xs]
return [x / sum(xs) for x in xs]
このコードなら、温度が1ならば確率通りで、温度が下がっていくといい感じに格差が広がっていきそうです。温度がゼロの場合には例外が出ますけど、温度を0にしたいのは本番の試合だけで、本番ではなにもこんな面倒な関数を通さずに単純にargmaxしちゃえばオッケー。なので、temperatureが0の場合は無視して、本番でnext_actionするための関数を書きます。
def pv_mcts_next_action_fn(model):
def pv_mcts_next_action(state):
return state.legal_actions[np.argmax(pv_mcts_scores(model, 20, state))]
return pv_mcts_next_action
試合の際に必要なのはstateだけを引数にする関数で、でも、pv_mcts_scores()にはそれ以外の引数が必要だったので、関数を返す関数として作成しました。関数型プログラミングって本当に便利ですな。そうそう、プレイアウトが不要になる分だけ深く読めるはずなので、試行回数はテキトーに減らしておきました。
深層学習
では、このあたりで先送りにしてきた深層学習絡みの部分を。
深層学習ってのは脳のニューロンを模した構造を、処理が楽になるようにベクトル演算で実現して、で、ベクトルつながりで画像処理のフィルター(深層学習では、何故か畳み込みと呼びます)を組み入れた結果、脳ともニューロンともあまり関係がなくなったように見えるニューラル・ネットワークで処理します。このニューラル・ネットワークを使う場合のプログラムへの最も大きな影響は、入力も出力も固定長の数値のベクトルになるということ。数値で表現できないものはダメですし、たとえ数値であってもゲームの合法手のような局面によって数が変わる可変長な情報そのままも扱えません。
マルバツはここまで数値で表現できているので数値問題はクリアなのですけど、固定長問題は解決が必要です。なので、贅沢ですけど最大の場合の長さを使うことにしましょう。マルバツの場合で言うと、ポリシーを長さ9のベクトルにしちゃうわけ。価値は長さ1のベクトル。幸いなことに、マルバツの局面は3✕3✕2の固定長にできます(「3✕3」は盤面の縦と横で、「✕2」は自分と敵)にできます。マルやバツが書き込まれたマスは1、そうでないマスは0となります)。「マルは「1」でバツは「2」にすれば3✕3だけで済んで経済的じゃん」って考え方は、深層学習ではダメ。というのも、先程単語が出てきた畳み込みってのが、何らかの量を表現しているものが順序よく並んでいる場合にだけ使えるテクニックなんですよ。バツはマルの2倍などという関係はありませんので、分割して同じに扱わなければなりません。畳み込みの元になった画像処理の画像データでも、青と赤と緑を別の数値で表現するでしょ?
というわけで、今回作成するニューラル・ネットワークの入力と出力は、以下の図のようになりました。
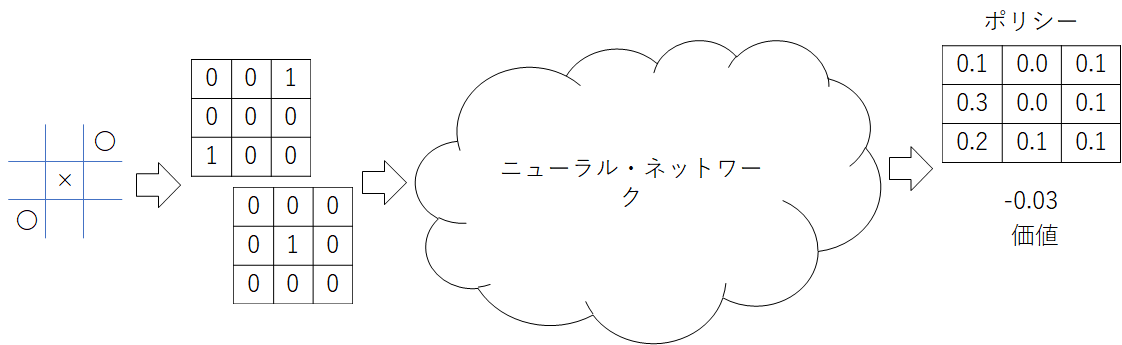
あとはニューラル・ネットワークの中身を決めるだけ……なんですけど、AlphaZeroのニューラル・ネットワークが採用したResidual Networkってのは数年前から大流行しているごく当たり前の構造なので、特別に説明するような事柄がないんですよね。過去にKerasでのコードを作っていましたので、そこから適当にコピー&ペーストしました。
from funcy import *
from keras.layers import Activation, Add, BatchNormalization, Conv2D, Dense, GlobalAveragePooling2D, Input
from keras.models import Model, save_model
from keras.regularizers import l2
def computational_graph():
WIDTH = 128 # AlphaZeroでは256。
HEIGHT = 16 # AlphaZeroでは19。
def ljuxt(*fs):
return rcompose(juxt(*fs), list)
def add():
return Add()
def batch_normalization():
return BatchNormalization()
def conv(channel_size):
return Conv2D(channel_size, 3, padding='same', use_bias=False, kernel_initializer='he_normal', kernel_regularizer=l2(0.0005))
def dense(unit_size):
return Dense(unit_size, kernel_regularizer=l2(0.0005))
def global_average_pooling():
return GlobalAveragePooling2D()
def relu():
return Activation('relu')
def softmax():
return Activation('softmax')
def tanh():
return Activation('tanh')
def residual_block():
return rcompose(ljuxt(rcompose(batch_normalization(),
conv(WIDTH),
batch_normalization(),
relu(),
conv(WIDTH),
batch_normalization()),
identity),
add())
return rcompose(conv(WIDTH),
rcompose(*repeatedly(residual_block, HEIGHT)),
global_average_pooling(),
ljuxt(rcompose(dense(9)),
rcompose(dense(1), tanh())))
ニューラル・ネットワークという名前を使うのはちょっと恥ずかしいので、関数名はcomputational_graph()、計算グラフにしました。こんな簡単なコードですけど、これでResidual Networkは完成です。出力が固定長云々に対応しているのは最後の2行で、dense(9)でポリシー用の長さ9のベクトルを、dense(1)で価値用の長さ1のベクトルを作成しています(AlphaZeroではこの部分も多段になっているみたいですけど、マルバツは簡単なので1層にしちゃいました)。ポリシーについては、dense()の結果をそのまま出力にします。一般的にはこのあとに何らかの活性化関数を入れるのですけど、合法手以外のポリシーは使わないわけで、非合法な手を含んでいる今はできることがありませんから。価値は-1から1の値になっていて欲しいので、tanhを使用しました。あと、なんかやけにコードがスッキリしているなぁって感じるのは、関数型プログラミングのテクニックを使っているからです。詳細はここで。
で、この計算グラフから処理を呼び出す際に必要となるモデルを作成するコードは、以下の通り。
model = Model(*juxt(identity, computational_graph())(Input(shape=(3, 3, 2))))
入力の3✕3✕2に相当するのが、shape=(3, 3, 2)の部分です。
今回は、モデルを作る、そのモデルを使うPV MCTSで対戦して学習データを溜める、溜めた学習データを使ってモデルを学習させる……というステップを踏みますから、深層学習のサンプル・コードみたいにモデルを作成したら即学習ってわけにはいきません。だから、とりあえず、このモデルは保存して終わりにしちゃいましょう。
save_model(model, './model/0000.h5')
……えっと、保存するのは1個だけでよいのかな? 皆様、これまでの説明を読んでいるときに「本当にそんな簡単な仕組みでうまく行くの?」という疑念がわきませんでしたか? 実はその疑念は正しくて、やってみるとうまく行ったりうまく行かなかったりするんです。データを溜めて学習させたらかえって弱くなっちゃった、みたいな感じ。この事態への対策として、訓練用の候補生を別途保存しておくことにしましょう。
save_model(model, './model/candidate/0000.h5')
チャンピオン同士を対戦させてデータを作成して、そのデータで候補生を訓練して、そしてチャンピオンと候補生を戦わせて勝った方を次のチャンピオンにする仕組みです。学習一回の単位で見ると強くなったり弱くなったりするんですけど、傾向としてはだんだん強くなっていくので、このやり方なら最強のチャンピオンが残り続けるはず。
あとは、後回しにしていたpredict()を実装しておきましょう。
import numpy as np
from funcy import *
def to_x(state):
def pieces_to_x(pieces):
return (1.0 if pieces & 0b100000000 >> i else 0.0 for i in range(9))
return np.array(tuple(mapcat(pieces_to_x, (state.pieces, state.enemy_pieces)))).reshape(2, 3, 3).transpose(1, 2, 0)
def predict(model, state):
x = to_x(state).reshape(1, 3, 3, 2)
y = model.predict(x, batch_size=1)
policies = y[0][0][list(state.legal_actions)]
policies /= sum(policies) if sum(policies) else 1
return policies, y[1][0][0]
to_x()は入力用の3✕3✕2の行列を作る関数です(Kerasでは、入力をx、出力をyと名付ける慣習があるみたい)。上のコードで使用しているNumPyは、癖があって時々辛いけど、とてもとても便利です。たとえばNumPyのarrayではarray[(1, 3, 4)]と書くと[array[1], array[3], array[4]]が返ってくる機能があって、それを利用しているのがpoliciesに値を代入する部分のy[0][0][list(state.legal_actions)]です。これだけで、ニューラル・ネットワークの制限に縛られた固定長のベクトルから、可変長な合法手それぞれのポリシーに変換されます。で、今回は手の確率にしておきたい(そうしないと、next_child_node()の式た正しく動かない気がする)ので、合計値で割り算しています。あと、ニューラル・ネットワークの出力はベクトル2つのはずなのに添字が一個多く見えるのは、ニューラル・ネットワークでは複数の処理をバッチとして処理するため。今回はbatch_size=1なので、2つ目の添字に無条件で[0]を指定しました。入力のxの方も、reshape()で先頭に1を追加しています。
セルフ・プレイ
では、データ取りのためにチャンピオン同士に対戦してもらいましょう。学習データの保存には、Pythonのpickleを使用しました。入力(の元)となるstatesと、出力の正解となるysを生成して、pickleで保存します。
import numpy as np
import pickle
from datetime import datetime
from funcy import *
from keras.models import load_model
from pathlib import Path
from pv_mcts import boltzman, pv_mcts_scores
from tictactoe import State, popcount
MAX_GAME_COUNT = 500 # AlphaZeroでは25000。
MCTS_EVALUATE_COUNT = 20 # AlphaZeroでは1600。
TEMPERATURE = 1.0
def first_player_value(ended_state):
if ended_state.lose:
return 1 if (popcount(ended_state.pieces) + popcount(ended_state.enemy_pieces)) % 2 == 1 else -1
return 0
def play(model):
states = []
ys = [[], None]
state = State()
while True:
if state.end:
break
scores = pv_mcts_scores(model, MCTS_EVALUATE_COUNT, state)
policies = [0] * 9
for action, policy in zip(state.legal_actions, boltzman(scores, 1.0)):
policies[action] = policy
states.append(state)
ys[0].append(policies)
state = state.next(np.random.choice(state.legal_actions, p=boltzman(scores, TEMPERATURE)))
value = first_player_value(state)
ys[1] = tuple(take(len(ys[0]), cycle((value, -value))))
return states, ys
def write_data(states, ys, game_count):
y_policies, y_values = ys
now = datetime.now()
for i in range(len(states)):
with open('./data/{:04}-{:02}-{:02}-{:02}-{:02}-{:02}-{:04}-{:02}.pickle'.format(now.year, now.month, now.day, now.hour, now.minute, now.second, game_count, i), mode='wb') as f:
pickle.dump((states[i], y_policies[i], y_values[i]), f)
def main():
model = load_model(last(sorted(Path('./model').glob('*.h5'))))
for i in range(MAX_GAME_COUNT):
states, ys = play(model)
print('*** game {:03}/{:03} ended at {} ***'.format(i + 1, MAX_GAME_COUNT, datetime.now()))
print(states[-1])
write_data(states, ys, i)
if __name__ == '__main__':
main()
うーん、特に書くことないなぁ……。あ、ごめんなさい。面倒だったので、ボルツマン分布の温度は1.0固定にしてしまいました。
学習
先程のプログラムを実行すると学習データができますから、そのデータを使って学習させましょう。といっても作業の殆どはKerasがやってくれますから、とても簡単です。
import numpy as np
import pickle
from funcy import *
from keras.callbacks import LearningRateScheduler
from keras.models import load_model, save_model
from pathlib import Path
from pv_mcts import to_x
from operator import getitem
def load_data():
def load_datum(path):
with path.open(mode='rb') as f:
return pickle.load(f)
states, y_policies, y_values = zip(*map(load_datum, tuple(sorted(Path('./data').glob('*.pickle')))[-5000:])) # AlphaZeroはランダムで抽出。
return map(np.array, (tuple(map(to_x, states)), y_policies, y_values))
def main():
xs, y_policies, y_values = load_data()
model_path = last(sorted(Path('./model/candidate').glob('*.h5')))
model = load_model(model_path)
model.compile(loss=['mean_squared_error', 'mean_squared_error'], optimizer='adam')
model.fit(xs, [y_policies, y_values], 100, 100,
callbacks=[LearningRateScheduler(partial(getitem, tuple(take(100, concat(repeat(0.001, 50), repeat(0.0005, 25), repeat(0.00025))))))])
save_model(model, model_path.with_name('{:04}.h5'.format(int(model_path.stem) + 1)))
if __name__ == '__main__':
main()
はい、これだけ。AlphaZeroはSGDというオプティマイザーを使ったらしいのですけど、私はTensorFlowのチュートリアルが使っていたAdamを使用しました。だって、Adamだと学習が速いんだもん。数式が分からなかったので速い理由はカケラも分かってないけどな。損失関数は、フィーリングで二乗誤差にしています。あと、学習率を少しずつ下げるコールバックをテキトーに設定しました。最高の精度を実現して論文書いてやるぜって場合じゃなければ、テキトーでもそれなりの精度が出るんですよ。
評価
あとは、学習させた候補とチャンピオンの対戦です。といっても、セルフ・プレイからデータ保存の部分を抜いて、勝率を調べる処理を追加した程度です。
import numpy as np
from datetime import datetime
from funcy import *
from keras.models import load_model
from pathlib import Path
from pv_mcts import boltzman, pv_mcts_scores
from shutil import copy
from tictactoe import State, popcount
MAX_GAME_COUNT = 100 # AlphaZeroでは400。
MCTS_EVALUATE_COUNT = 20 # AlphaZeroでは1600。
TEMPERATURE = 1.0
def first_player_point(ended_state):
if ended_state.lose:
return 1 if (popcount(ended_state.pieces) + popcount(ended_state.enemy_pieces)) % 2 == 1 else 0
return 0.5
def play(models):
state = State()
for model in cycle(models):
if state.end:
break;
state = state.next(np.random.choice(state.legal_actions, p=boltzman(pv_mcts_scores(model, MCTS_EVALUATE_COUNT, state), TEMPERATURE)))
return first_player_point(state)
def update_model():
challenger_path = last(sorted(Path('./model/candidate').glob('*.h5')))
champion_path = last(sorted(Path('./model').glob('*.h5')))
copy(str(challenger_path), str(champion_path.with_name(challenger_path.name)))
def main():
models = tuple(map(lambda path: load_model(last(sorted(path.glob('*.h5')))), (Path('./model/candidate'), Path('./model'))))
total_point = 0
for i in range(MAX_GAME_COUNT):
if i % 2 == 0:
total_point += play(models)
else:
total_point += 1 - play(tuple(reversed(models)))
print('*** game {:03}/{:03} ended at {} ***'.format(i + 1, MAX_GAME_COUNT, datetime.now()))
print(total_point / (i + 1))
average_point = total_point / MAX_GAME_COUNT
print(average_point)
if average_point > 0.5: # AlphaZeroでは0.55。マルバツだと最善同士で引き分けになるので、ちょっと下げてみました。
update_model()
if __name__ == '__main__':
main()
……コードの重複を排除していなくてごめんなさい。セルフ・プレイとほとんど同じなので、どーにも書くことがありません。あ、AlphaZeroでは勝率が55%を超えたら入れ替えだったのですけど、マルバツだと最強AI同士の対戦で勝率50パーセントになるので、50パーセントを超えたら入れ替えに変更しました。
実行
これでプログラムはすべて完成です。実行してみましょう。モデル作成のコードをinitialize.py、セルフ・プレイをself_play.py、学習をtrain.py、評価をevaluate.pyという名前で保存して、以下のシェル・プログラムで実行させます。
#!/bin/sh
python initialize.py
for i in `seq 1 10` ; do
python self_play.py
python train.py
python evaluate.py
done
とりあえず、10サイクル回してみましょう。NVIDIA GTX 1080 TiをThunderbolt 3で繋いだ私のラップトップPCで、2時間くらいかかりました。
で、成果は?
サイクルが回ったので、どれくらい強くなったのか試してみる……前に、少し待って。
PV MCTSにはランダム性がなくて、だから、同様にランダム性がないアルファ・ベータ法と前回のように何回も対戦させても無意味です。あと、さっき知ったのですけど、ミスをする可能性があるプレイヤーの場合、マルバツは先手が有利なんですね。先手は初手でどこを指しても最悪でも引き分けに持ち込めるのですけど、後手は先手に合わせた適切な手を指さないと負けが決まってしまう(Wikipediaでさっき勉強しました)。そもそも、先手は先に動けますし、最後に余分に一手指せますし。
というわけで、検証方法を変更しましょう。まずは、どこまで正確に指せるのかを調べることにします。
from funcy import *
from keras.models import load_model
from pathlib import Path
from pv_mcts import pv_mcts_next_action_fn
from tictactoe import State, popcount, random_next_action, monte_carlo_tree_search_next_action, nega_alpha_next_action
def main():
def test_correctness(next_action):
return ((next_action(State().next(0)) in (4,)) +
(next_action(State().next(2)) in (4,)) +
(next_action(State().next(6)) in (4,)) +
(next_action(State().next(8)) in (4,)) +
(next_action(State().next(4)) in (0, 2, 6, 8)) +
(next_action(State().next(1)) in (0, 2, 4, 7)) +
(next_action(State().next(3)) in (0, 4, 5, 6)) +
(next_action(State().next(5)) in (2, 3, 4, 8)) +
(next_action(State().next(7)) in (1, 4, 6, 8)) +
(next_action(State().next(0).next(4).next(8)) in (1, 3, 5, 7)) +
(next_action(State().next(2).next(4).next(6)) in (1, 3, 5, 7)))
pv_mcts_next_action = pv_mcts_next_action_fn(load_model(last(sorted(Path('./model').glob('*.h5')))))
nega_alpha_correctness = test_correctness(nega_alpha_next_action)
print('{:4.1f}/11 = {:.2f} nega_alpha'.format(nega_alpha_correctness, nega_alpha_correctness / 11))
pv_mcts_correctness = test_correctness(pv_mcts_next_action)
print('{:4.1f}/11 = {:.2f} pv_mcts'.format(pv_mcts_correctness, pv_mcts_correctness / 11))
monte_carlo_tree_search_correctness = sum(map(lambda _: test_correctness(monte_carlo_tree_search_next_action), range(100))) / 100
print('{:4.1f}/11 = {:.2f} monte_carlo_tree_search'.format(monte_carlo_tree_search_correctness, monte_carlo_tree_search_correctness / 11))
で、試してみると……。
$ python test_corrctness.py
11.0/11 = 1.00 nega_alpha
10.0/11 = 0.91 pv_mcts
5.9/11 = 0.54 monte_carlo_tree_search
惜しい……。1つだけ間違えちゃいました(深層学習のニューラル・ネットワークの初期値はランダムなので、初期値ガチャを頑張ればパーフェクトになりますけど)。まぁ、モンテカルロ木探索よりも遥かに優秀なので良し! ついでですから、先手と後手を入れ替えながらのモンテカルロ木探索との対戦もやってみましょう。
print(test_algorithm((pv_mcts_next_action, monte_carlo_tree_search_next_action)))
print(test_algorithm((monte_carlo_tree_search_next_action, pv_mcts_next_action)))
0.91 # PV MCTSが先手の場合の、先手の勝率
0.575 # モンテカルロ木探索が先手の場合の、先手の勝率
うん、かなり手を抜いた簡易実装なのに、モンテカルロ木探索よりも強いです。念の為、更にサイクルを回してみましょう。一日かけて、あと90回、合計して100回のサイクルを回してみました。
11.0/11 = 1.00 nega_alpha
11.0/11 = 1.00 pv_mcts
6.2/11 = 0.56 monte_carlo_tree_search
0.94 # PV MCTSが先手の場合の、先手の勝率
0.515 # モンテカルロ木探索が先手の場合の、先手の勝率
やりました! パーフェクトです! 対モンテカルロ木探索の勝率も上がりました! 今年49歳になるおっさんでも作れちゃうくらいに簡単なのに、AlphaZeroってすげー。